Large-System Analysis of MIMO Detection
Why We Need Asymptotic Analysis
In Chapter 13 we derived the LMMSE (Wiener) estimator for linear models . Its MSE and output SINR can be written explicitly in terms of , , and the input covariance. But in a large MIMO system with, say, transmit and receive antennas, these expressions hide the scaling behavior we actually care about. They depend on the specific realization of through eigenvalues that fluctuate from channel to channel.
The point is that as the dimensions grow, the fluctuations vanish. A suitably normalized SINR concentrates around a deterministic value that depends only on the aspect ratio and the SNR. This is the power of random matrix theory for wireless systems: we replace the intractable dependence on by a scalar fixed-point equation. The result is not a rough estimate — it is sharp, in the sense that the gap between the random SINR and its deterministic limit is .
Definition: Empirical Spectral Distribution
Empirical Spectral Distribution
Let be an Hermitian matrix with real eigenvalues . Its empirical spectral distribution (ESD) is the random probability measure When converges (weakly, almost surely) to a deterministic measure as , we call the limiting spectral distribution (LSD).
The ESD summarizes all spectral information into a single measure. Traces of polynomials and inverses of become integrals against : .
Definition: Stieltjes Transform
Stieltjes Transform
The Stieltjes transform of a probability measure on is For a Hermitian matrix with ESD , the associated (random) Stieltjes transform is .
The Stieltjes transform is an analytic function on (upper half-plane) that encodes the measure . The inversion formula (Plemelj) recovers the density: . Convergence of the ESD is equivalent to pointwise convergence of on .
Theorem: Marchenko-Pastur Law
Let be an matrix whose entries are i.i.d. complex (or real) with mean zero, variance , and finite fourth moment. Let and consider the Gram matrix . As with , the ESD of converges almost surely to the Marchenko-Pastur distribution with density
The eigenvalues of a large i.i.d. Gram matrix do not cluster around the mean . They spread out over the interval , and the width of this interval is . When , the matrix is tall and full rank; when , there are zero eigenvalues because is rank-deficient. The point is that a large random MIMO channel has an extreme spectrum — its smallest singular value approaches , not zero, provided .
Set up the fixed-point equation for the Stieltjes transform
Let . Using the Sherman-Morrison formula, peel off one column of and write where is the matrix with column removed.
Concentrate the quadratic forms
For i.i.d. with variance , the quadratic form concentrates around which in turn converges to (by the rank-one perturbation lemma, removing one column does not change the Stieltjes transform in the limit).
Derive the Marchenko-Pastur equation
Summing the diagonal entries and taking : This simplifies to the quadratic
Invert to obtain the density
Solving the quadratic and taking the root with on , then applying Plemelj's inversion formula , yields the density in the theorem.
Marchenko-Pastur Density for Several Aspect Ratios
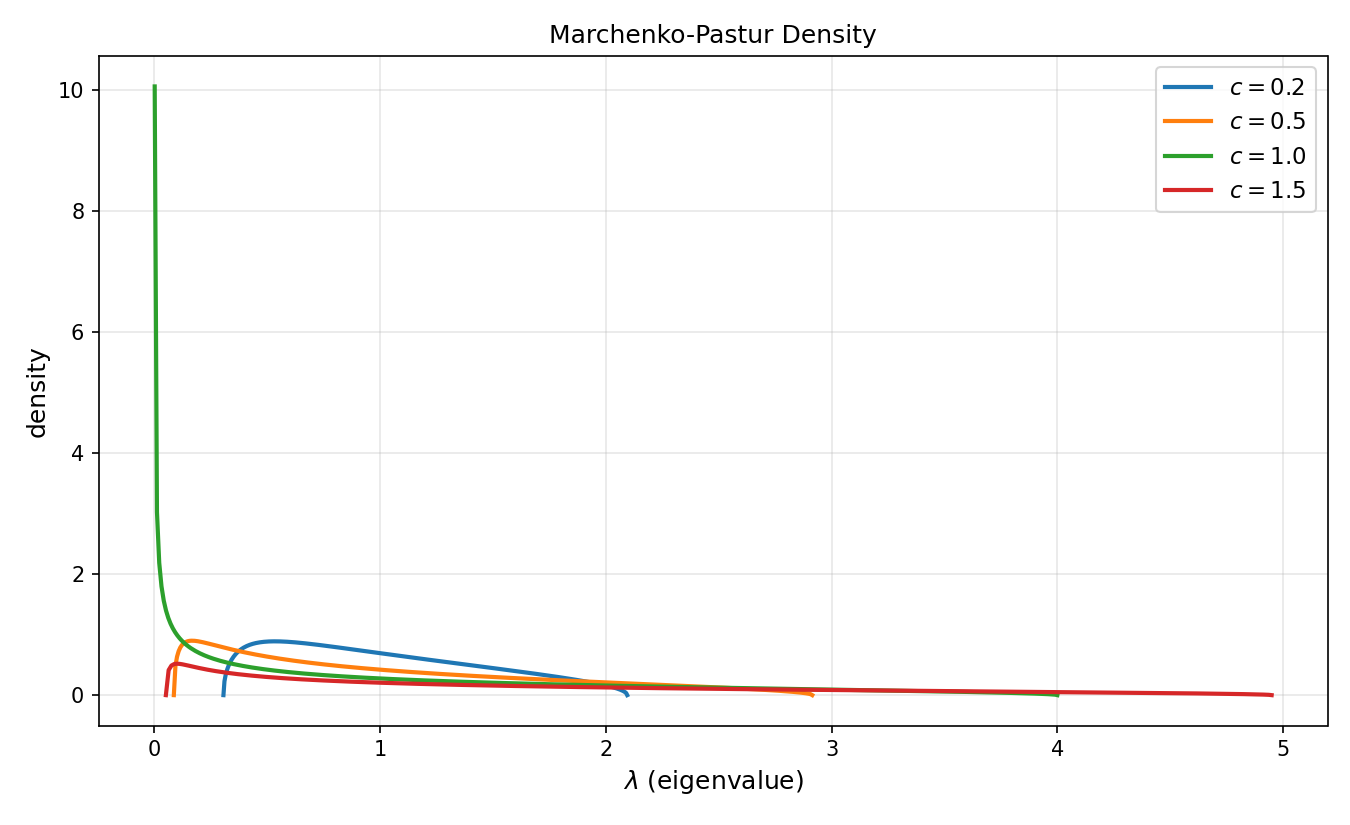
Marchenko-Pastur: Empirical vs. Asymptotic Spectrum
Compare the eigenvalue histogram of a finite random Gram matrix (with i.i.d. ) to the Marchenko-Pastur density. Adjust the dimensions and watch the histogram lock onto the limit.
Parameters
Definition: LMMSE Detector SINR (Finite )
LMMSE Detector SINR (Finite )
Consider the MIMO channel with and . The LMMSE detector for stream is with . Equivalently, . Its output SINR for stream is where is with column removed.
Theorem: Deterministic Equivalent of the LMMSE SINR
Assume the entries of are i.i.d. . In the large-system limit with , the output SINR of the LMMSE detector on any stream converges almost surely to where satisfies the fixed-point equation Equivalently, the limiting SINR is the unique positive solution of
The deterministic equivalent replaces a random quantity (the SINR, which depends on the channel realization) by a scalar depending only on and . The fixed-point admits an elegant interpretation: in the large-system limit each stream "sees" an effective interference-plus-noise with variance equal to a self-consistent function of its own SINR. The circular definition resolves into a quadratic. This is the simplest instance of the replica symmetric prediction in random matrix theory.
Rewrite the SINR using the matrix inversion lemma
By the Sherman-Morrison formula, equals appropriately. After algebra, ).
Trace lemma
For independent of with i.i.d. entries of variance , the quadratic form concentrates: . The normalized trace converges to the Stieltjes transform: .
Close the fixed-point equation
Writing and the Marchenko-Pastur fixed-point equation for , eliminating , and using (after algebra) yields the cubic-free form .
Verify the fixed-point is unique
The map is strictly decreasing in for , so it has a unique fixed point. Standard RMT arguments (Tse-Hanly 1999) show that .
Example: Solving the LMMSE Fixed-Point Equation
For a MIMO system with (two receive antennas per transmit stream) and dB, compute the asymptotic LMMSE SINR . Compare to the single-user SISO rate .
Set up the fixed point
dB . The fixed-point equation is .
Solve the quadratic
Multiply out: , so . Expanding: , i.e., . The positive root is .
Convert to spectral efficiency
The per-stream rate is bits/s/Hz. The single-user SISO rate at the same SNR is bits/s/Hz. The loss is about 0.47 bits per stream — this is the price paid for multi-stream interference even with optimal linear processing.
Total spectral efficiency
With streams the total rate scales as , so doubling (reducing from 1 to 0.5) is worth much more than a single SISO link even though the per-stream rate drops.
Why the Fixed-Point is Benign
The fixed-point equation is not a convex optimization per se, but the map whose fixed point we seek is a contraction on in the metric . Fixed-point iteration converges globally and monotonically from any starting point — a reliable property that matters when we need to evaluate the limit over thousands of pairs for system design.
Deterministic Equivalent vs. Monte Carlo
Compare the asymptotic SINR predicted by the fixed-point equation to the empirical SINR distribution over random realizations. As grows, the empirical distribution concentrates at the fixed point.
Parameters
Large-System Approximations in System Design
System designers routinely use large-system deterministic equivalents for early-stage link budget analysis. For , the prediction error of the asymptotic SINR formula is typically under 0.3 dB. This allows sweeping thousands of configurations analytically rather than running Monte Carlo.
- •
Formulas assume i.i.d. Rayleigh fading — correlated channels require the generalized Silverstein equation.
- •
Per-realization outage behavior is lost — only ergodic metrics are captured.
- •
Deterministic equivalents are asymptotic: below the variance of the SINR matters.
Historical Note: From Nuclear Physics to Wireless
1967-1999The Marchenko-Pastur law (1967) was published in a Soviet mathematics journal with no applied motivation — it generalized Wigner's semicircle law from nuclear physics to rectangular matrices. Three decades later, David Tse and Steve Hanly (1999) recognized that the same distribution governs the SINR of CDMA receivers when the number of users and the spreading gain both grow to infinity. Sergio Verdú and Shlomo Shamai independently obtained closely related results. This opened a highly productive line of research that is now the standard analytical tool for massive MIMO and cell-free networks.
Why This Matters: Cell-Free Massive MIMO
In cell-free massive MIMO, each user is served by a large pool of distributed access points. The combined channel matrix is thin and tall, with . The Marchenko-Pastur analysis here predicts the achievable per-user SINR after centralized LMMSE processing, and informs the centralized-vs-distributed tradeoff explored in Book MIMO Chapter 18.
Common Mistake: Forgetting the Aspect Ratio Regime
Mistake:
Applying the Marchenko-Pastur formulas in the square regime , where the density diverges at and small eigenvalues dominate the MSE.
Correction:
At , the smallest eigenvalue of scales as , so the LMMSE matrix inversion is ill-conditioned. The deterministic equivalent is still valid, but the constants in the error bound blow up as . In practice, stay away from — add regularization or use more receive antennas.
Quick Check
For (four times more rows than columns), what is the lower edge of the Marchenko-Pastur density?
.
The Marchenko-Pastur Law Emerging
Key Takeaway
In the large-system limit, the random output SINR of an LMMSE detector on an i.i.d. Rayleigh MIMO channel concentrates around a deterministic value characterized by a simple scalar fixed-point equation in and . This replaces per-realization simulation with an analytic formula — an indispensable tool for massive MIMO system design.
Deterministic Equivalents for Correlated Channels
The CommIT group contributed to extending deterministic-equivalent techniques from the classical i.i.d. Marchenko-Pastur setting to isometric (Haar) precoders and correlated channels. This is the mathematical foundation behind many of the system-level predictions in Book MIMO.